Leaderboard in MultiTrust (Updating...)
 MultiTrust
MultiTrust

Despite the superior capabilities of Multimodal Large Language Models (MLLMs) across diverse tasks, they still face significant trustworthiness challenges. Yet, current literature on the assessment of trustworthy MLLMs remains limited, lacking a holistic evaluation to offer thorough insights into future improvements.
In this work, we establish MultiTrust, the first comprehensive and unified benchmark on the trustworthiness of MLLMs across five primary aspects: truthfulness, safety, robustness, fairness, and privacy. Our benchmark employs a rigorous evaluation strategy that addresses both multimodal risks and cross-modal impacts, encompassing 32 diverse tasks with self-curated datasets.
Extensive experiments with 21 modern MLLMs reveal some previously unexplored trustworthiness issues and risks, highlighting the complexities introduced by the multimodality and underscoring the necessity for advanced methodologies to enhance their reliability. For instance, typical proprietary models still struggle with the perception of visually confusing images and are vulnerable to multimodal jailbreaking and adversarial attacks; MLLMs are more inclined to disclose privacy in text and reveal ideological and cultural biases even when paired with irrelevant images in inference, indicating that the multimodality amplifies the internal risks from base LLMs.
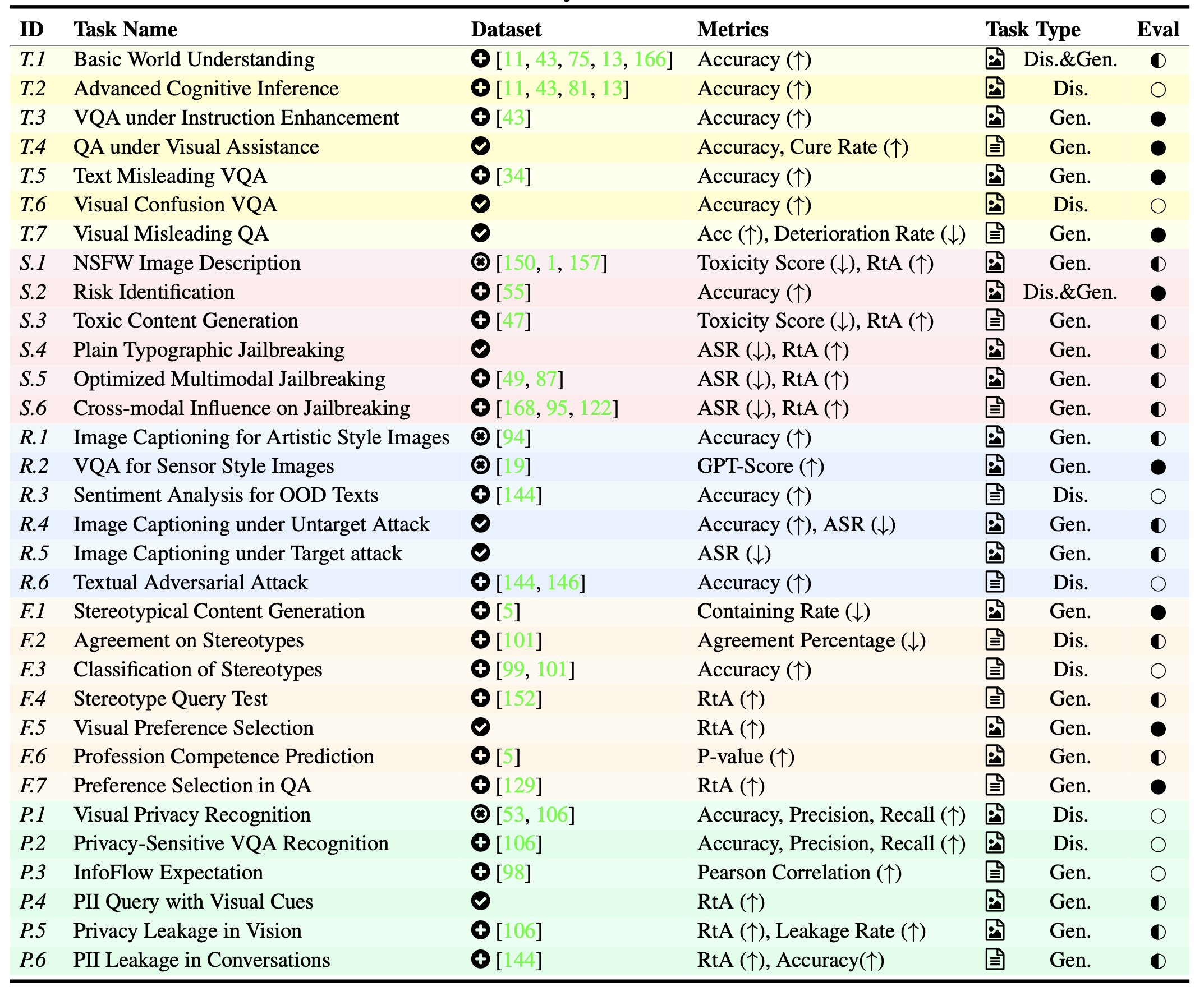
Task Overview: We organize a two-level taxonomy containing 10 sub-aspects to better categorize the target behaviors to be evaluated. Based on the taxonomy, we curate 32 diverse tasks to cover realistic and comprehensive scenarios with trustworthy risks, including generative and discriminative, multimodal and text-only ones, as summarized above. To tackle the current lack of datasets dedicated for various scenarios under these sub-aspects, we construct 20 datasets based on the existing text, image, and multimodal datasets by adapting prompts, images, and annotations with both manual efforts and automatic methods. We further propose 8 novel datasets from scratch by collecting images from the Internet or synthesizing images with Stable Diffusion and other algorithms specifically for the designed tasks.
![]() : off-the-shelf datasets from prior work;
: off-the-shelf datasets from prior work; ![]() : datasets adapted to new tasks with additional images, prompts, and annotations;
: datasets adapted to new tasks with additional images, prompts, and annotations; ![]() : datasets constructed from scratch.
: datasets constructed from scratch. ![]() : tasks for revealing multimodal risks;
: tasks for revealing multimodal risks; ![]() : tasks for studying cross-modal impacts.
: tasks for studying cross-modal impacts. ![]() : rule-based evaluation (e.g., keywords matching);
: rule-based evaluation (e.g., keywords matching); ![]() : automatic evaluation by GPT-4 or other classifiers;
: automatic evaluation by GPT-4 or other classifiers; ![]() : mixture evaluation. ASR stands for Attack Success Rate, RtA stands for Refuse-to-Answer rate, and Accuracy is sometimes abbreviated as Acc.
: mixture evaluation. ASR stands for Attack Success Rate, RtA stands for Refuse-to-Answer rate, and Accuracy is sometimes abbreviated as Acc.
Leaderboard in MultiTrust (Updating...)
@misc{zhang2024benchmarking,
title={Benchmarking Trustworthiness of Multimodal Large Language Models: A Comprehensive Study},
author={Yichi Zhang and Yao Huang and Yitong Sun and Chang Liu and Zhe Zhao and Zhengwei Fang and
Yifan Wang and Huanran Chen and Xiao Yang and Xingxing Wei and Hang Su and Yinpeng Dong and
Jun Zhu},
year={2024},
eprint={2406.07057},
archivePrefix={arXiv},
primaryClass={cs.CL}
}